
GitHub Copilot: Código, Aplicaciones y Modelos. (GenAI ágil y divertida).

Las bases de datos vectoriales, el código abierto e la IA generativa son tres factores fundamentales para el éxito en la creación y el desarrollo de aplicaciones y modelos de lenguaje avanzados. ¿Por qué son decisivos para la rentabilidad y el futuro de la digitalización avanzada con retornos visibles y demostrables?
Demos un repaso a este gran activador de la creación de valor empresarial. Al trabajar de forma combinada con estas tecnologías podemos crear modelos personalizados más inteligentes, eficientes y capaces de comprender y generar valor para la Empresa.
Vayamos por pasos entrando en materia para que explores por qué queremos que fijes en tu roadmap una estrategia tecnológica superior que te devuelva la inversión realizada.
La combinación de bases de datos vectoriales, código abierto e IA generativa permite crear Aplicaciones más sofisticadas, con ello, más competitivas y, por tanto capaces de realizar tareas más complejas cuyo objetivo final consiste en crear, de un modo ágil y rentable, la excelencia y la satisfacción de las que muchos hablan como rasgo propio en su digitalización pero, seamos sinceros, muy pocos tienen.
- Bases de datos vectoriales Los vectores permiten representar conceptos y relaciones de manera más rica y compleja que las palabras aisladas, fundamental para tareas como la comprensión del lenguaje natural, donde el significado de una frase va más allá de la suma de sus palabras. Al almacenar información en forma de vectores, podemos realizar búsquedas basadas en similitud semántica, en lugar de solo coincidencias exactas para encontrar información relevante y contextualizada. Las bases de datos vectoriales pueden manejar grandes cantidades de datos de manera eficiente para entrenar modelos de IA de gran escala.
- Código abierto El código abierto fomenta la colaboración entre investigadores y desarrolladores, lo que acelera el progreso y permite construir sobre el trabajo de otros. Al hacer público el código, se fomenta la transparencia y la reproducibilidad de los resultados, lo que aumenta la confianza en los modelos. La comunidad de código abierto es muy diversa, lo que contribuye a la creación de modelos más equitativos y representativos.
- IA generativa La IA generativa puede crear grandes cantidades de datos sintéticos de alta calidad, siendo útil para entrenar modelos en dominios donde los datos reales son limitados o costosos de obtener. Los datos sintéticos pueden utilizarse para aumentar los conjuntos de datos existentes, lo que mejora el rendimiento de los modelos. La IA generativa abre posibilidades importantes en la generación de valor a través de texto, imagen y código, lo que impulsa el desarrollo de nuevas aplicaciones y servicios.
Las bases de datos vectoriales dan acceso a una herramienta estratégica de alta importancia para generar datos sintéticos de calidad. Esta capacidad es fundamental para el entrenamiento de modelos de Machine Learning y Deep Learning con una amplia gama de usos prácticos, fomentando la excelencia y creatividad empresarial dando lugar a la productividad y la eficiencia, desde la visión por computadora hasta el procesamiento del lenguaje natural como ejemplos más relevantes, pero no únicos.
Nuestra recomendación: Usa bases de datos vectoriales para generar datos sintéticos.
- Datos sintéticos para entrenar modelos de visión por computadora Al construir una base de datos vectorial de imágenes médicas reales, se pueden generar nuevas imágenes con características similares, pero con variaciones aleatorias para entrenar modelos de diagnóstico que requieran grandes cantidades de datos, especialmente cuando los datos reales son limitados o contienen información sensible. Puedes crear bases de datos vectoriales de objetos en diferentes poses, tamaños y entornos. Luego, utilizando técnicas de generación de imágenes, puedes generar nuevas imágenes de esos objetos en situaciones nunca vistas, enriqueciendo el entrenamiento de modelos de detección y clasificación de objetos.
- Datos sintéticos para entrenar modelos de lenguaje natural Al representar conversaciones en un espacio vectorial, puedes generar diálogos más naturales y variados para entrenar chatbots y asistentes virtuales que requieren comprender y responder a una amplia gama de preguntas y solicitudes. Si tienes una base de datos vectorial de un idioma con pocos recursos, puedes generar nuevos textos sintéticos que mantengan la estructura y el estilo del lenguaje original, ayudando a entrenar modelos de traducción o generación de texto más precisos.
- Datos sintéticos para entrenar modelos de recomendación Puedes generar perfiles de usuarios sintéticos basados en características demográficas y de comportamiento de usuarios reales. Estos perfiles pueden utilizarse para entrenar modelos de recomendación que sugieran productos o servicios personalizados. Al generar interacciones usuario-producto sintéticas, puedes evaluar la efectividad de diferentes estrategias de recomendación y optimizar los algoritmos de recomendación.
- Datos sintéticos para entrenar modelos de series temporales Puedes generar series temporales sintéticas con patrones anómalos para entrenar modelos de detección de anomalías. Esto es útil en aplicaciones como el monitoreo de sistemas industriales o la detección de fraudes. Puedes generar series temporales que representen diferentes escenarios económicos o climáticos para evaluar la robustez de los modelos de pronóstico.
Curiosamente, al contrario de lo que pueda parecer en un principio, los datos sintéticos generados a partir de bases de datos vectoriales suelen ser más diversos y representativos que los datos reales.
Puedes controlar las características de los datos sintéticos generados, lo que te permite crear datos específicos para tus necesidades de entrenamiento. Los datos sintéticos pueden utilizarse, igualmente, para aumentar el tamaño de los conjuntos de entrenamiento, agilizando el entrenamiento de los modelos y mejorando su rendimiento.
Con datos sintéticos puedes proteger la privacidad de los usuarios al evitar la exposición de datos personales sensibles.
¿Quién dijo que escribir código fuese aburrido?
GitHub Copilot es la herramienta para desarrolladores que está modificando la forma en que escribimos código. Trabajar con datos vectoriales, código abierto y generative AI, Copilot ofrece una experiencia de programación más eficiente, creativa y, por qué no decirlo, divertida.
- GitHub Copilot hace sugerencias automáticas de fragmentos de código con lo que escribir código va a ser más ágil para escalar valor para la excelencia. Además, puede ayudarte a aprender nuevas tecnologías al sugerir sintaxis y estructuras de código. Automatizando tareas repetitivas, te proporciona el tiempo para concentrar los esfuerzos en los aspectos más creativos de la programación lo que te hace más competitivo y por tanto rentable en tu inversión tecnológica.
GitHub ha sido recientemente nombrado líder en este Cuadrante Mágico de Gartner.
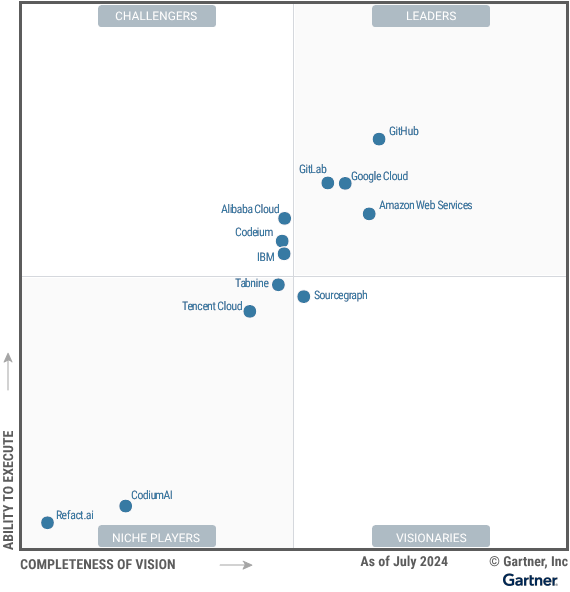
Las sugerencias de Copilot están basadas en buenas prácticas de programación, lo que ayuda a mantener un código limpio y eficiente.
GitHub utiliza una amplia variedad de canales de retroalimentación, incluidos consejos asesores de clientes y comunicación directa con los equipos de productos de GitHub Copilot, para garantizar que las aportaciones de los usuarios influyan directamente en el desarrollo de productos. GitHub Copilot se centra en mejorar la productividad de los desarrolladores y la calidad del código mediante sugerencias de código impulsadas por IA y asistencia contextual.
¡GitHub Copilot funciona! 1. Tu código se convierte en un vector numérico. 2. Se busca el vector más cercano en la base de datos de Copilot. 3. Se genera una sugerencia de código basada en el vector más cercano y en los modelos de lenguaje generativo.
Cosas importantes que debes seguir investigando a fondo ( y si quieres con nosotros) para materializar con nuestro equipo de desarrolladores tus ideas y crear la excelencia que necesitas.
- GitHub Copilot Extensions cuenta con el respaldo de un creciente ecosistema de socios comerciales y de código abierto, para permitir que los desarrolladores creen e implementen sin problemas dentro de sus entornos preferidos.
- GitHub está ampliando Copilot con funciones como Copilot Workspace para un entorno de desarrollo colaborativo nativo de IA, extensiones de Copilot para una integración perfecta de herramientas y seguridad y cumplimiento normativo mejorados. Sus operaciones están diversificadas geográficamente y sus clientes tienden a ser grandes organizaciones de diversos sectores.
- GitHub proporciona GitHub Copilot a los mantenedores activos de la comunidad de código abierto, así como a profesores y estudiantes de forma gratuita.


- Microsoft Azure
- Microsoft Dynamics 365
- Transformación Digital
- Inteligencia Artificial
- Power BI
- Machine Learning
- Soluciones de gestión empresarial
- Dynamics 365 Cárnicas
- Data Driven
- Azure AI
- Microsoft Cloud
- Microsoft Dynamics 365 Finanzas y Operaciones
- Microsoft Power Platform
- Business Intelligence
- Digitalización
- Ciberseguridad
- Dynamics 365 FO
- Analítica BI
- Sector Cárnico
- ERP CRM